

Cover photo by Alex Wong on Unsplash.
In a previous post I described the rationale behind our decision to abandon the secureCodeBox v1 and redesign the whole architecture. In this post I'll go into the details of this redesigned architecture.
The Architecture of secureCodeBox Version 2
In Kubernetes 1.17 they introduced a new concept of custom resources. The short idea is, that you may extend Kubernetes with your own resources additionally to the default ones shipped with Kubernetes. Why should you do this? The interesting part of Kubernetes is that it is a great tool for resource management. Solely it is the most important part of Kubernetes to automate the management of datacenter resources. In v1 we "abused" a BPMN engine for managing the scans and the associated resources were allocated all the time. But since the most important parts of the secureCodeBox (the scanners) are containers anyway, it makes sense to use a tool which is designed for managing such resources. So we came up with the idea to define the scanners as custom resources and replace the heavy Java based engine from v1 with a custom operator for Kubernetes. The whole idea to use Kubernetes as orchestrator for the scans is based upon a master thesis our core maintainer Jannik has written about Automatic Assessment of Applications Security Aspects running in Cloud Environments. The following diagram shows the new architecture of secureCodeBox v2.
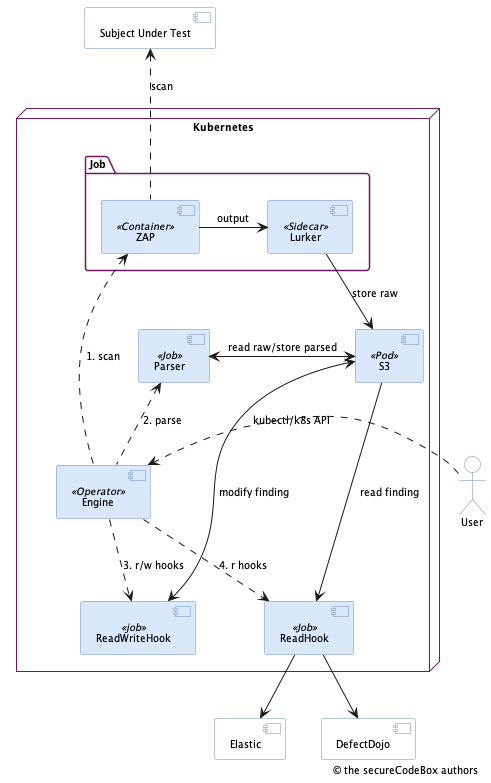
Legend:
- the dashed arrows are actions, e.g. calls to the Kubernetes API or doing a scan
- the solid arrows are data flows
- the solid purple boxes are part of the secureCodeBox v2
- the solid white boxes are external systems
Basic Idea
The basic idea of the new architecture is to define the scanners as custom resources and schedule them as jobs in Kubernetes. The UI to interact with secureCodeBox is simply the Kubernetes API and kubectl. So, how does a scan works in this new design?
- A new scan is triggered via Kubernetes API or kubectl.
- The operator submits a new scan job which consists of two containers:
- The scanner which is a simple container running the CLI tool like Zap or such (see full list of integrated scanners),
- and the lurker sidecar which is a generic container used by all scanners which siphons all output from the CLI scanner into a S3 storage. (By default secureCodeBox contains MinIO, but you can use any S3 compatible storage.)
- Then the operator starts a parser container job for this particular scanner which transforms the raw results into our well defined finding format and stores them back into the S3 storage.
- After that the operator submits jobs for all registered read-write hooks. This is a concept to allow post processing of findings. E.g. you can adjust fields or enrich the findings with data from other systems.
- As last step the operator submits jobs for all registered read hooks. This is a concept to exfiltrate data from the secureCodeBox into external systems (e.g. notifications via chat or email, import into a VMS like DefectDojo etc.).
Design Goals
What about the design goals from the v1 architecture? Let's go through each of them:
It should be possible to easily integrate new scanners.
The scanners are containers as in v1, but way more simpler: There is no need to jam the CLI tool into some glue code which transforms the incoming arguments and the outgoing results from the tool. You just simply create an image with the tool expecting its arguments and spitting out its result as is. The parsing of the result is done in a separate container. So you simply write a companion parser image for your scanner image which transforms the stored raw result into a generic findings format.
Writing such a companion parser is quite simple because we provide an SDK to help you with that. If you are curious about this topic you can read our documentation about integrating a new scanner.
All components should be loosely coupled to easily swap them.
The basic idea oft loosely coupling all components is nearly the same as in v1. We separate all components into individual services. Certainly more lightweight than in v1 because we drastically reduced the complexity of the individual scanner images. Most of the components are individual containers communicating via well defined APIs (Kubernetes API instead of own REST API) to each other.
But there is also a major improvement over the v1 architecture. As mentioned in the previous articles we had a web UI in v1. This introduced accidentally a tight coupling between the scanners and the engine because for each new scanner or feature of one it was mandatory to adapt the UI. We introduced a tight coupling through the backdoor. This was a major pain in the ass when it came to releases because we had to release everything at once. All the scanners and the engine which were located in individual repositories. This resulted in a complete day job to make a release.
With the new architecture we strictly decoupled scanners and engine. The scanners are custom resources and the engine is an operator. Both well known concepts of Kubernetes decoupled by the API provided by Kubernetes. If you now add a new scanner there is no need to touch the operator. This architecture has one downside. It is tightly coupled to Kubernetes. So it is not possible to run secureCodeBox without Kubernetes or a future system which provides the same API. But we are willing to accept this tradeoff due to all the benefits we receive.
The whole deployment should run anywhere (local, VMs, Cloud, etc.) and scale.
This does not hold anymore! For secureCodeBox v2 a Kubernetes cluster is mandatory as environment. Of course you can run secureCodeBox on any virtual machine, cloud or local, as far as you install Kubernetes. We put up with this trade-off because Kubernetes is ubiquitous nowadays and the benefits as mentioned above are worth it.
The definition and implementation of a scan process should be easy.
We defined our own YAML syntax to declare a scan process. This is way easier than generating BPMN models in Java as for secureCodeBox v1. You can see it in action at our how to section. It's simply writing YAML 😸
New Design goals
Since we are already making a breaking change we could add some new design goals which we considered of importance:
Scanners Does Not Run All the Time Idling
This is the main reason why we use Kubernetes as underlying platform: Kubernetes manages when to start and stop containers. With this new architecture containers only run when they have work to do. The only component which runs all the time is the operator and maybe the S3 storage if you use the built in instead of an external one.
Easy Use in Cloud Based Projects
In environments where projects share large scale Kubernetes clusters it is possible to install the operator as a central component. The scanners instead can be installed and run in the namespaces of the project. So they can use secureCodeBox complete independently. They need not beg some cluster administrators to install new scanners or change a scan process. The projects can do this on their on behalf inside their project namespace.
No Need of Central CI/CD
In v1 you needed a system which triggers a scan. Typically this was a CI/CD system which made a REST API call to the engine. This is not necessary anymore. You can simply run a scan with kubectl. Also you can schedule regularly scans directly inside Kubernetes. But despite that you can trigger a scan from your CI/CD anyway. Just simply call the Kubernetes API.
CLI First
Since we learned that the full bloated web UI of secureCodeBox v1 was only a nice feature for management slides, we completely abandoned such a UI. Our main target audience are developers which are used to command line interfaces and embrace DevSecOps where you want to automate as much as possible. A CLI is obviously way more convenient to automate than a web UI.
But anyway you may want some web UI to manage your findings. At the moment we provide simply Kibana and Elasticsearch to visualize them. But we're working hard on better solutions. Additionally you can import all the findings in any system you want with a custom read hook.
Cascading Scans
We had early the demand to trigger subsequent scans based on previous scan results. A very simple but common use case is to scan a host for open ports and afterwards scan these ports with dedicated scanners. In v1 we used a galactic workaround to achieve this: We first executed a Nmap scan and stored the result. Then we executed separate scans for the found open ports. The orchestration was done with Jenkins pipelines and some Python scripts. Actually we hacked a separate "engine" on top of the main BPMN engine because we couldn't extend it to execute sub process models in a process model with separate scopes. You see this was not a very well engineered solution 😉
Since we introduced in v2 our own YAML syntax to define scans, we had the opportunity to just extend it for the purpose of cascading scans. We introduced the Cascading Rule custom resource. With this you can specify a scanner to be scheduled based on previous findings.